
KoRaptor
150M size SLM built with single GPU
I only used a single Nvidia RTX 3090 GPU to pretrain a 150M Korean Language Model — fully from scratch. Built a tokenizer with SentencePiece, using LatentMoE architecture, gathering datasets and finetuned. Open-source on GitHub and Hugging Face.
GPU Killer & Failures.
There were many failures throughout this project. To begin with, the computer died. I pushed it far beyond its limit. The main issue was with the power supply. Ironically, I had even written code to pause every 200 steps just to cool things down, but it worsen the problem. I technically did "stress test" on my computer. But the problem didn't stop there. There were plenty of software issues, too. Let me list them out.
- Each epoch took about 36 hours.
- The dataset was too small to train effectively
- The system temperature kept rising despite cooldown intervals
- Compatibility issues with huggingface-hub tools — I thought uploading to Hugging Face would help, but transformers didn’t support LatentMoE properly
Architecture
I followed Deepseek's module and added MoE(Mixture of Experts) architecture from scratch. (Back then, there was no R2 model which Deepseek applied the MoE.) I first pretrained with Korean Wiki and AI hub dataset which is mainly consisted of news articles. I used SentencePiece to make a tokenizer but, one thought pass through my mind. Korean is super easy to learn but has a massive learning curve. This is because unlike English, Korean has diverse morpheme. So, I decided to make a tokenizer out of morpheme, using Mecab and SentencePiece. Advantage of using morpheme as a tokenizer is first, the model can truely catch the pattern of the grammar of language and can increase the size of the datasets.Pretrain Results
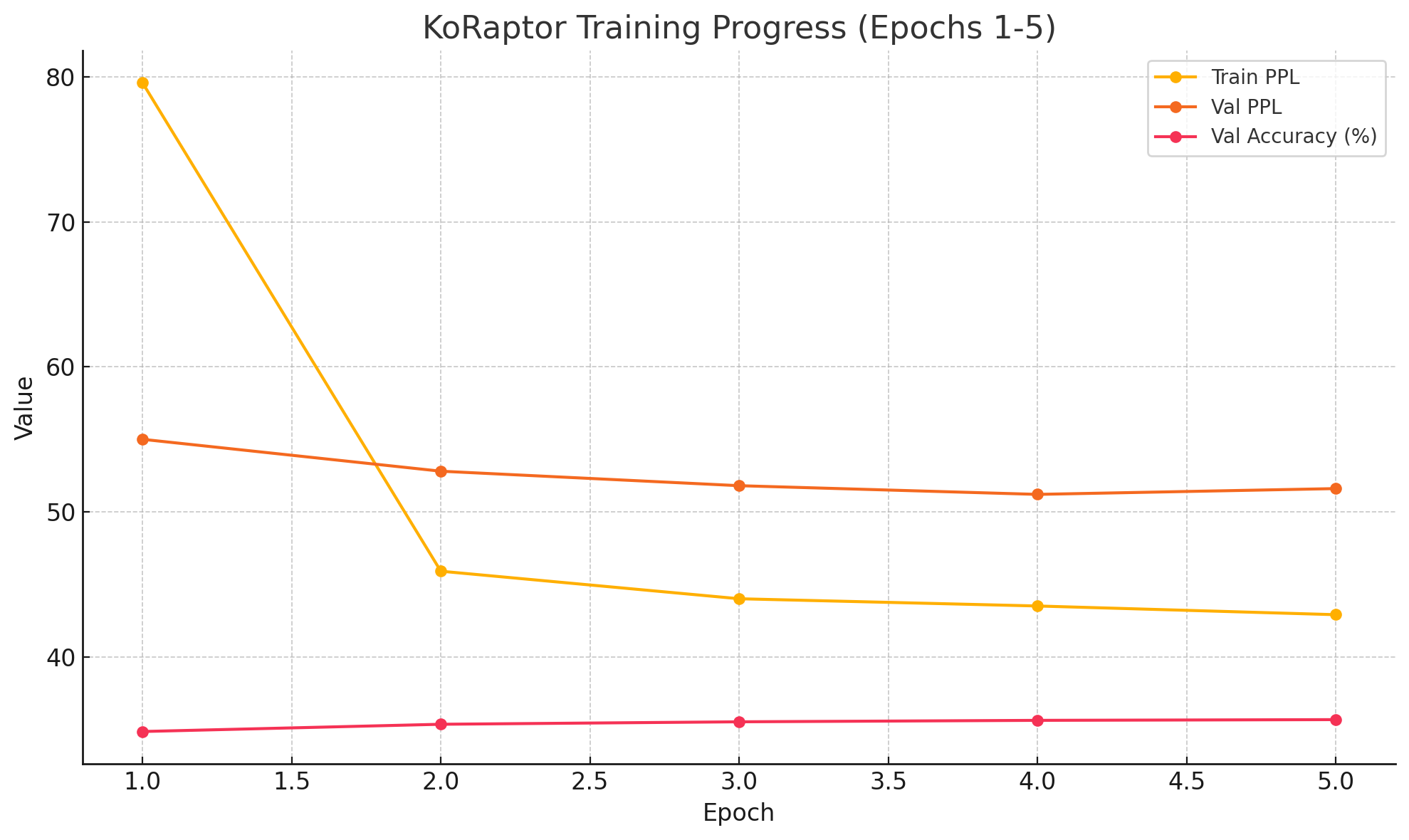
I stopped at 5th epoch for pretraining for two reasons.
First, validation perplexity started increasing after the 4th epoch, peaking by the 6th.
Since perplexity is the exponential of the loss, this indicated that the loss was also increasing.
Second, each epoch required around 36 hours to complete.
Given that the 4th epoch showed the best validation perplexity, I decided to fine-tune this model as a chatbot.
(Although I mentioned it breifly, this stage involved a lot of trial and error. Initially, I attempted to train a 1B model first,
but it couldn't run on my GPU efficiently. So changed to 72M, read Chinchilla Scaling Law paper, found the optimal model size that can be pretrained. This took about a month.)
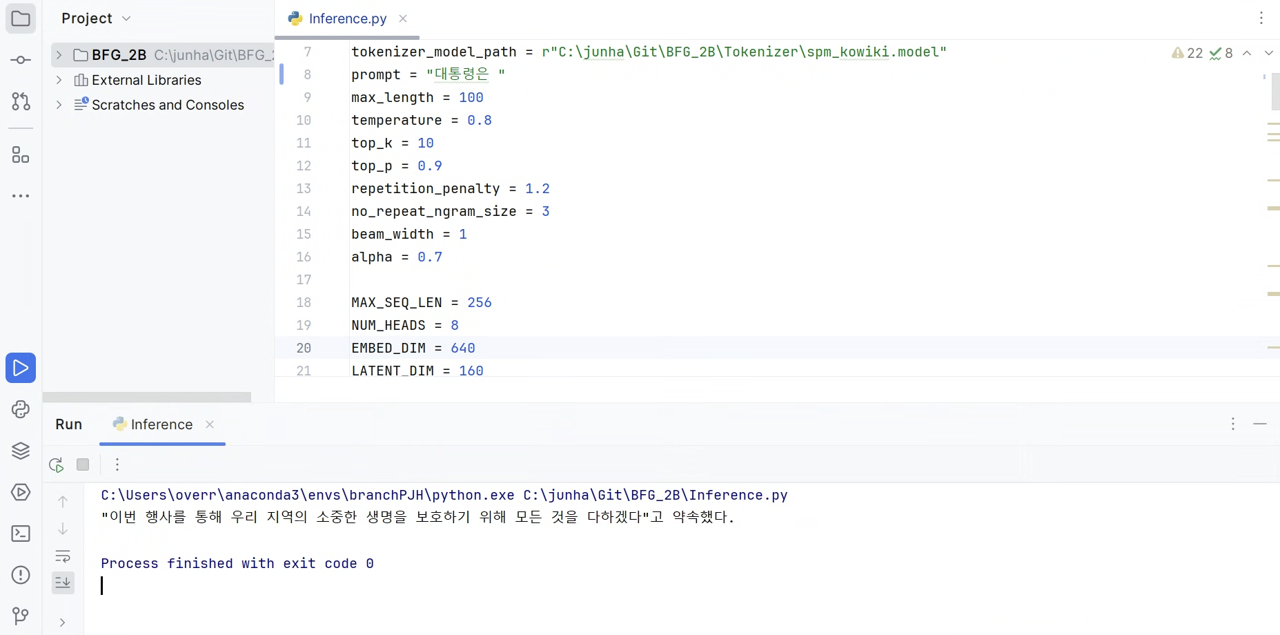
As you can see from the image, the Next Token Prediction is actually not bad. (input: "대통령은", output: "이번 행사를 통해 우리 지역의 소중한 생명을 보호하기 위해 모든 것을 다하겠다"고 약속했다.") For those who don't understand korean, my prompt was "The president has". Raptor model predicted the next sentence as "promised that 'Through this ceremeony, we will do our best to protect precious lives living in our community.'". You can tell that the model understood how korean works.
Fine-tune Results
I fine-tuned with Korean multi-turn dataset from AI Hub. First, I preprocessed to make a row of prompt and answer set. I forgot to mask out the prompt which is the user input, the first fine-tuned model kept whining. So, I masked the user prompt and re-trained, finally made the chatbot to answer like chatbot. But, due to the lack of finetuning dataset and small parameter, it lacks performance. I will improve this model and build English version Raptor, too.