
HiabGPT
Help I accidentally built GPT from scratch!
“If in doubt, code it out.” This phrase comes from my online teacher, Daniel Bourke, who taught me how to build AI models. He emphasizes the importance of visualization, because artificial intelligence is essentially a black box. You don’t really know what’s going on inside. It’s packed with math, weights and biases, gradient descent, loss functions, and more. These concepts can feel intimidating at first. But I believe the best way to learn something is to dive straight into building a system. Everyone learns differently, but for me, jumping into the deep end definitely worked. That’s why, when I got curious about GPT, I decided to try building one myself.
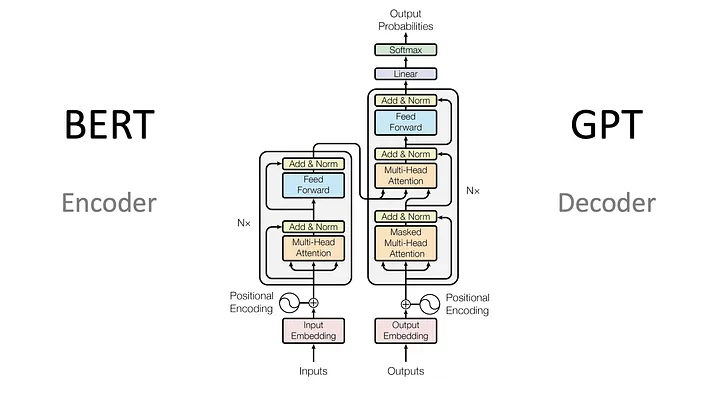
Transformer Architecture
The paper “Attention Is All You Need”, which quite literally transformed how AI works, introduced the attention mechanism. This mechanism involves computing Query, Key, and Value vectors between all tokens.
Basically, the Transformer is made up of two parts: the encoder and the decoder. The encoder turns input words into an array of numbers, making them easier to work with mathematically. The decoder, on the other hand, turns those numbers back into words. Because of this, encoders are better at understanding meaning, while decoders are better at generating text.
Help! I accidently built GPT from scratch Part.2
Extraction Summary & Issues
I used the prompt of "오늘 날씨가 " and waited for the next token prediction. The output was like the following:
"오늘 날씨가 가격 가격 가격 가격 가격미미미"
Yes, this is weird. The model has memorized token sequences without understanding the semantics — just as early GPTs did before scaling. You need to train about 10 times more datasets for the size of parameters to make a model understand the semantics.
As we’ve discussed, building or training a model with PyTorch is relatively straightforward. However, creating a fully functional large language model (LLM) that understands semantics and generates coherent, meaningful sentences is far more complex.
Let’s consider a scenario where GPU resources are limited. Due to VRAM constraints, you’re only able to train on a smaller dataset like WikiText-103 (103M tokens). You might start by training on WikiText-103 (103M) and then move on to a larger dataset such as BookCorpus (1B). However, this approach introduces two key challenges.
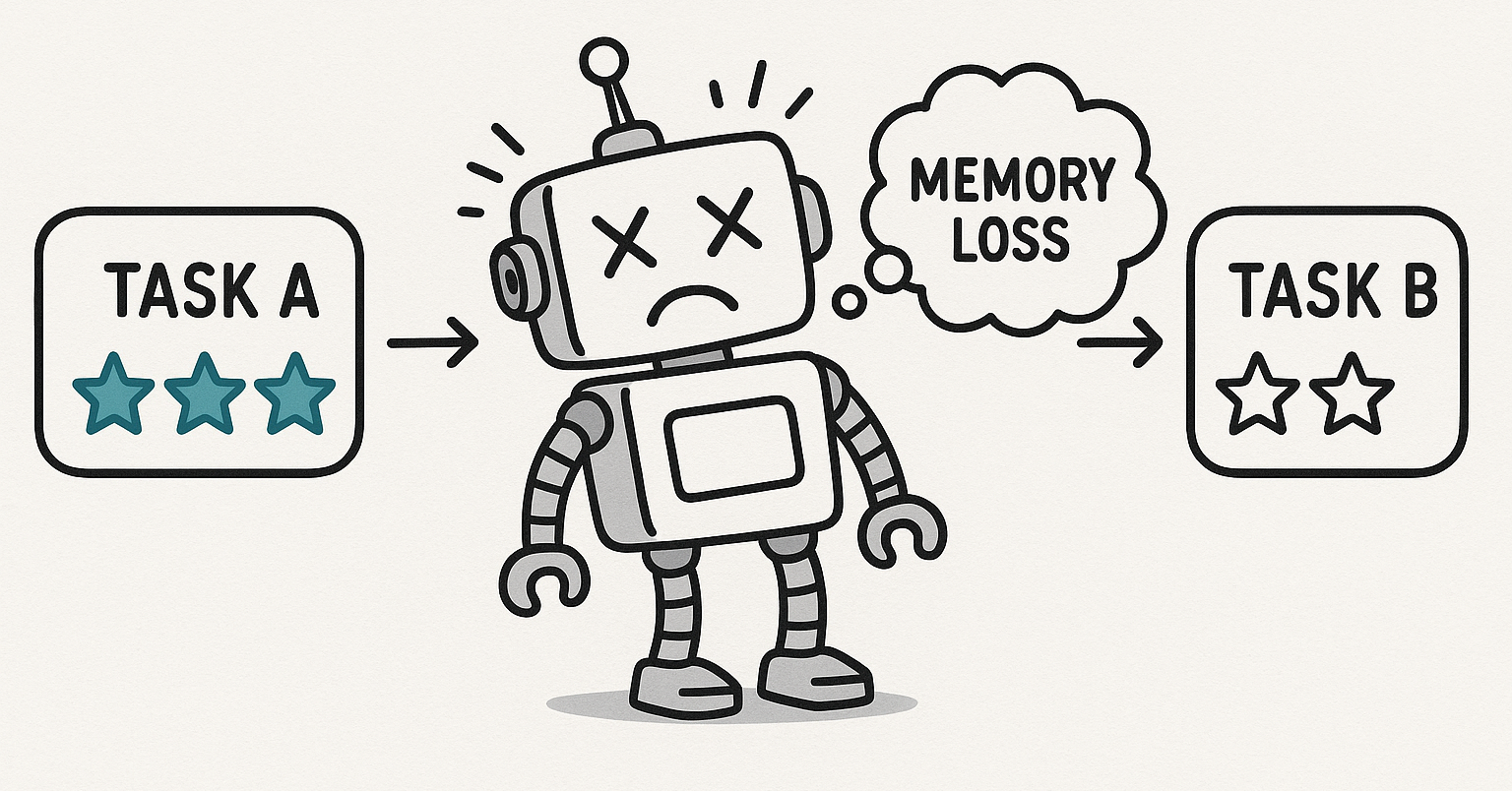
The first issue is the tokenizer. Since the datasets differ, you need to reset or retrain your tokenizer. While this is manageable, the second issue is more serious: Catastrophic Forgetting.
What is Catastrophic Forgetting?
Catastrophic Forgetting occurs when a model forgets previously learned information as it learns new data. This is a significant issue in sequential or continual learning scenarios. During the training on the second dataset, the model’s weights adjust to fit the new data, often at the expense of the knowledge gained from the first dataset. In practice, this means the model “forgets” what it learned from WikiText-103 once it starts training on BookCorpus. To prevent this, it’s generally necessary to interleave or mix multiple datasets during training rather than training on them sequentially. Additionally, due to scaling laws, training larger models requires a significantly larger amount of data. For example, training a 10B parameter model typically requires around 100B tokens.